Qu'est-ce que le Web Scraping? Comment collecter des données à partir de sites Web
Publicité
Les racleurs Web collectent automatiquement des informations et des données qui ne sont généralement accessibles qu'en visitant un site Web dans un navigateur. En effectuant cette opération de manière autonome, les scripts de nettoyage Web ouvrent un monde de possibilités en exploration de données, analyse de données, analyse statistique, etc.
Pourquoi le raclage Web est utile
Nous vivons à une époque où l'information est plus facilement disponible que n'importe quel autre moment. L’infrastructure en place utilisée pour transmettre ces mots que vous lisez est un moyen de transmettre plus de connaissances, d’opinions et d’informations qu’elle n’a jamais été accessible aux gens de leur histoire.
Si bien, en fait, que le cerveau de la personne la plus intelligente, optimisé à 100% d'efficacité (quelqu'un devrait faire un film à ce sujet), ne serait toujours pas en mesure de contenir 1 / 1000ème des données stockées sur Internet uniquement aux États-Unis .
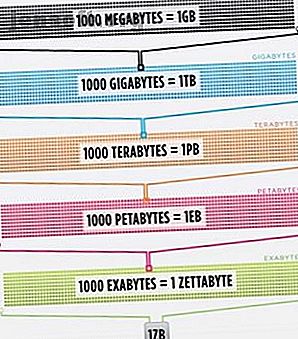
Cisco estimait en 2016 que le trafic sur Internet dépassait le zettaoctet, soit 1 000 000 000 000 000 000 000 octets, soit un sextillion d'octets (allez-y, rigolez à sextillion). Un zettaoctet correspond à environ quatre mille ans de diffusion en continu de Netflix. Ce serait équivalent à si, lecteur intrépide, vous diffusiez The Office du début à la fin sans arrêter 500 000 fois.

Toutes ces données et informations sont très intimidantes. Tout n'est pas juste. Cela n’intéresse guère la vie quotidienne, mais de plus en plus d’appareils transmettent ces informations à partir de serveurs du monde entier, jusque dans les yeux et le cerveau.
Comme nos yeux et notre cerveau ne peuvent pas vraiment gérer toutes ces informations, le Web scraping est devenu une méthode utile pour la collecte de données par programme à partir d’Internet. Web scraping est le terme abstrait pour définir l'acte d'extraire des données de sites Web afin de les sauvegarder localement.
Pensez à un type de données et vous pouvez probablement les collecter en grattant le Web. Vous pouvez rechercher et sauvegarder des listes d'immobilier, des données sportives, les adresses électroniques des entreprises de votre région et même les paroles de votre artiste préféré en écrivant un petit script.
Comment un navigateur obtient-il des données Web?
Pour comprendre les scrapers Web, nous devons d'abord comprendre comment fonctionne le Web. Pour accéder à ce site Web, vous avez soit tapé «makeuseof.com» dans votre navigateur Web, soit cliqué sur un lien provenant d'une autre page Web (indiquez-nous où, sérieusement, nous voulons savoir). De toute façon, les deux prochaines étapes sont les mêmes.
Tout d'abord, votre navigateur prendra l'URL que vous avez entrée ou sur laquelle vous avez cliqué (Astuce: survolez le lien pour voir l'URL située au bas de votre navigateur avant de cliquer dessus pour éviter d'être punk) et forme une «demande» d'envoi. à un serveur. Le serveur traitera ensuite la demande et renverra une réponse.
La réponse du serveur contient les données HTML, JavaScript, CSS, JSON et autres nécessaires pour permettre à votre navigateur Web de former une page Web pour votre plus grand plaisir.
Inspection d'éléments Web
Les navigateurs modernes nous permettent quelques détails concernant ce processus. Dans Google Chrome sous Windows, vous pouvez appuyer sur Ctrl + Maj + I ou cliquer avec le bouton droit de la souris et sélectionner Inspecter . La fenêtre présentera alors un écran ressemblant à ce qui suit.
Une liste d'options à onglets marque le haut de la fenêtre. L' onglet Réseau est à présent intéressant. Cela donnera des détails sur le trafic HTTP comme indiqué ci-dessous.
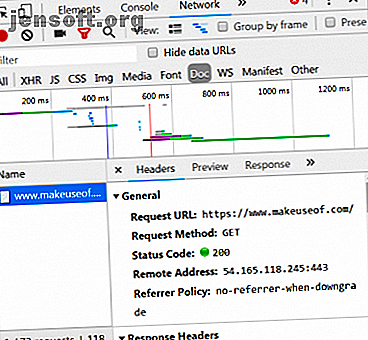
Dans le coin inférieur droit, nous voyons des informations sur la requête HTTP. Nous attendons l'URL et la "méthode" est une requête HTTP "GET". Le code d'état de la réponse est répertorié comme 200, ce qui signifie que le serveur a considéré la demande comme valide.
Sous le code d'état se trouve l'adresse distante, qui correspond à l'adresse IP publique du serveur makeuseof.com. Le client obtient cette adresse via le protocole DNS. Pourquoi modifier les paramètres DNS augmente votre vitesse Internet Pourquoi modifier les paramètres DNS augmente votre vitesse Internet La modification de vos paramètres DNS est l’une de ces modifications mineures qui peuvent générer des retours importants sur les vitesses Internet quotidiennes. Lire la suite .
La section suivante répertorie les détails de la réponse. L'en-tête de réponse contient non seulement le code d'état, mais également le type de données ou le contenu que contient la réponse. Dans ce cas, nous examinons «text / html» avec un encodage standard. Cela nous indique que la réponse est littéralement le code HTML pour rendre le site Web.
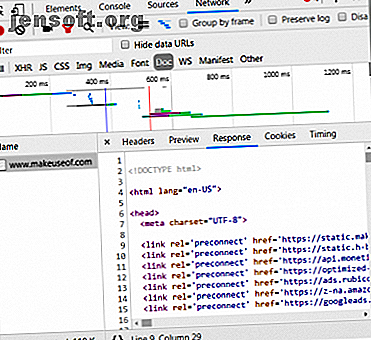
Autres types de réponses
De plus, les serveurs peuvent renvoyer des objets de données en réponse à une requête GET, au lieu de HTML uniquement pour le rendu de la page Web. Interface de programmation d'applications (ou API) d'un site Web Que sont les API et comment les API ouvertes modifient-elles Internet? Quelles sont les API et comment les API ouvertes modifient-elles Internet? Vous êtes-vous déjà demandé comment les programmes de votre ordinateur et des sites Web que vous visitez ont été «parlés»? l'un à l'autre? Read More utilise généralement ce type d'échange.
En parcourant l'onglet Réseau comme indiqué ci-dessus, vous pouvez voir s'il existe ce type d'échange. Lors de l’enquête sur le CrossFit Open Leaderboard, la demande de remplissage du tableau avec des données est affichée.
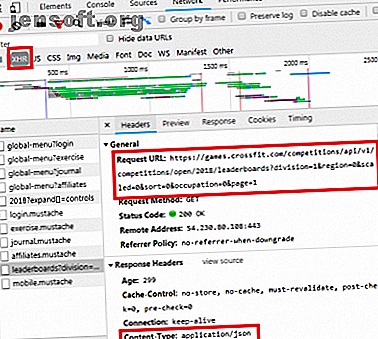
En cliquant sur la réponse, les données JSON sont affichées à la place du code HTML pour le rendu du site Web. Les données en JSON sont une série d'étiquettes et de valeurs, dans une liste hiérarchisée en couches.
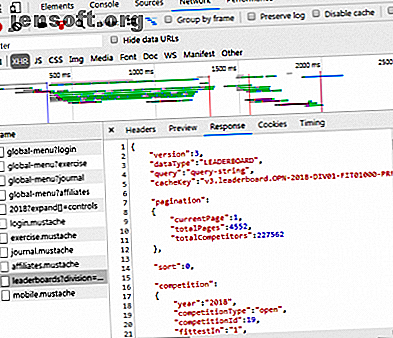
Analyser manuellement le code HTML ou parcourir des milliers de paires clé / valeur de JSON ressemble beaucoup à la lecture de la matrice. À première vue, cela ressemble à du charabia. Il peut y avoir trop d'informations pour les décoder manuellement.
Racleurs Web à la rescousse!
Maintenant, avant de demander la pilule bleue pour vous en sortir, sachez que nous n'avons pas à décoder manuellement le code HTML! L'ignorance n'est pas un bonheur, et ce steak est délicieux.
Un scraper Web peut effectuer ces tâches difficiles pour vous. L’API Scrapestack facilite l’élimination de sites Web pour les données L’API Scrapestack facilite l’élimination de sites Web pour les données Vous recherchez un scraper Web puissant et abordable? L'API scrapestack est libre de commencer et offre de nombreux outils pratiques. Lire la suite . Les frameworks de scraping sont disponibles en Python, JavaScript, Node et autres langages. L'un des moyens les plus simples de commencer à gratter est d'utiliser Python et Beautiful Soup.
Gratter un site web avec Python
La mise en route ne prend que quelques lignes de code, à condition que Python et BeautifulSoup soient installés. Voici un petit script pour obtenir la source d'un site Web et laisser BeautifulSoup l'évaluer.
from bs4 import BeautifulSoup import requests url = "http://www.athleticvolume.com/programming/" content = requests.get(url) soup = BeautifulSoup(content.text) print(soup) Très simplement, nous envoyons une requête GET à une URL, puis nous plaçons la réponse dans un objet. L'impression de l'objet affiche le code source HTML de l'URL. Le processus est comme si nous allions manuellement sur le site Web et cliquions sur Afficher la source .
Plus précisément, il s’agit d’un site Web qui publie des séances d’entraînement de style CrossFit tous les jours, mais seulement une par jour. Nous pouvons construire notre grattoir pour obtenir l'entraînement chaque jour, puis l'ajouter à une liste agrégée d'entraînements. Essentiellement, nous pouvons créer une base de données historique textuelle sur laquelle nous pouvons facilement faire une recherche.
La magie de BeaufiulSoup réside dans la possibilité de rechercher dans tout le code HTML à l'aide de la fonction findAll () intégrée. Dans ce cas spécifique, le site Web utilise plusieurs balises «sqs-block-content». Par conséquent, le script doit parcourir toutes ces balises et trouver celle qui nous intéresse.
En outre, il existe un certain nombre de
balises dans la section. Le script peut ajouter tout le texte de chacune de ces balises à une variable locale. Pour ce faire, ajoutez une simple boucle au script:
for div_class in soup.findAll('div', {'class': 'sqs-block-content'}): recordThis = False for p in div_class.findAll('p'): if 'PROGRAM' in p.text.upper(): recordThis = True if recordThis: program += p.text program += '\n' Voilà! Un racleur Web est né.
Mise à l'échelle de raclage
Deux chemins existent pour avancer.
Une façon d'explorer le raclage Web consiste à utiliser les outils déjà développés. Web Scraper (grand nom!) Compte 200 000 utilisateurs et est simple à utiliser. En outre, Parse Hub permet aux utilisateurs d’exporter des données récupérées dans Excel et Google Sheets.
De plus, Web Scraper fournit un plug-in Chrome qui permet de visualiser comment un site Web est construit. Le meilleur de tous, à en juger par leur nom, est OctoParse, un puissant racleur à interface intuitive.
Enfin, maintenant que vous connaissez l’arrière-plan du raclage Web, créez votre propre petit racleur Web pour pouvoir explorer et exécuter Comment construire un robot Web de base pour extraire des informations d’un site Web Comment créer un robot d’exploration Web de base pour extraire des informations d’un Site Web Avez-vous déjà voulu capturer des informations à partir d'un site Web? Vous pouvez écrire un robot pour naviguer sur le site et extraire ce dont vous avez besoin. En savoir plus sur lui-même est une entreprise amusante.
Explorez plus sur: Python, Web Scraping.